News: The HAPI FHIR Blog
The Growth of HL7 FHIR
One of the things we often talk about in the FHIR standards development community is where FHIR currently sits on Gartner's Hype Cycle. The hype cycle is a coarse measure of the trajectory of new technologies on a journey from being "new and exciting silver bullets" to eventually being "boring useful technologies".
When you are a proponent of a new technology (as I certainly am with FHIR), probably the most important aspect to remember about the hype cycle is that you really only ever know where you are at any given time long after that time has passed. In other words, it's fun to ask yourself "have we passed the Peak of Inflated Expectations yet?" but you really won't know until much later.
Speculating is perhaps a fool's errand. I probably shouldn't try but I can't help but wonder if we have passed the peak yet.
The trajectory of HAPI FHIR's growth is interesting. FHIR has been growing over the last few years by all kinds of metrics. The connectathons keep getting bigger, the number of vendors participating keeps on getting bigger, and FHIR DevDays keeps on getting bigger.
If I look at our website in Google Analytics, I am curious about the trajectory.
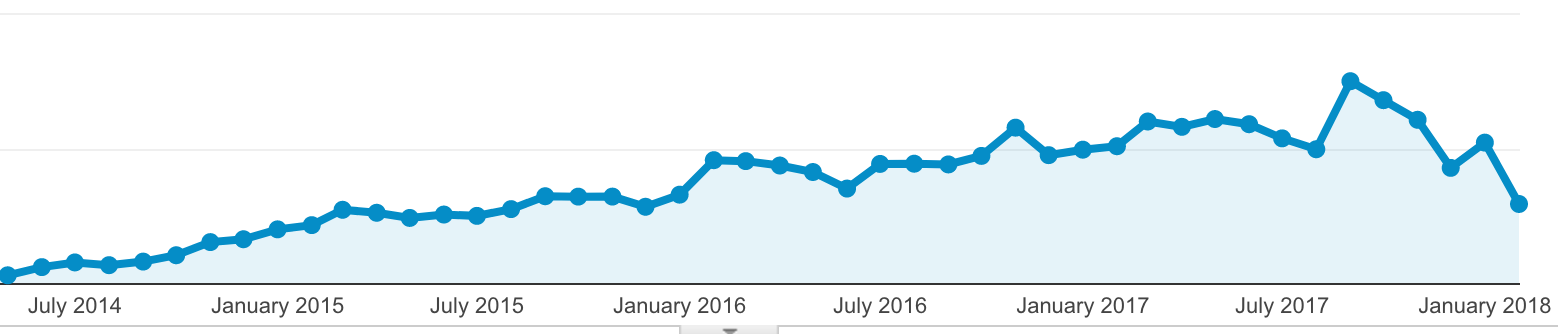
While HAPI FHIR has seen pretty steady growth over the last few years, that growth has been either tapering or at least very unstable over the last 8 months.
Certainly I don't think HAPI FHIR has stopped growing. The number of messages on the support forum and the number of people with big production implementations these days certainly doesn't suggest that; however, things have certainly been weird the last 8 months.
Let's look at interest in FHIR overall. The next thing to look at is the FHIR Google Trends graph, which measures the number of people searching for terms on Google (a pretty decent indicator of general interest). The following graph shows the last 4 years for FHIR.
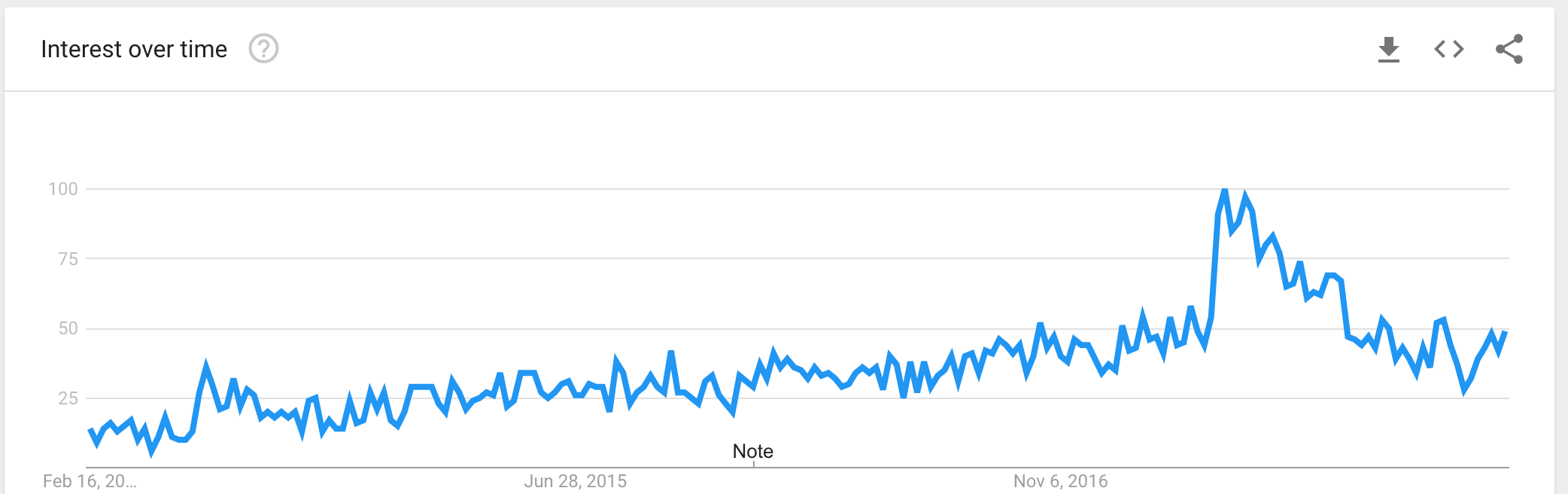
It would seem that FHIR itself saw a crazy explosion of interest back in May, too. That makes sense since FHIR R3 was released right before that peak.
Let's compare that with the graph for IHE. I don't think anyone would disagree that IHE sits firmly atop the Plateau of Productivity. Most people in the world of health informatics know what can be accomplished with IHE's profiles, and certainly I've worked with many organizations who use them to accomplish good things.
The FHIR and IHE Graph shows interest in FHIR in BLUE and IHE in RED.
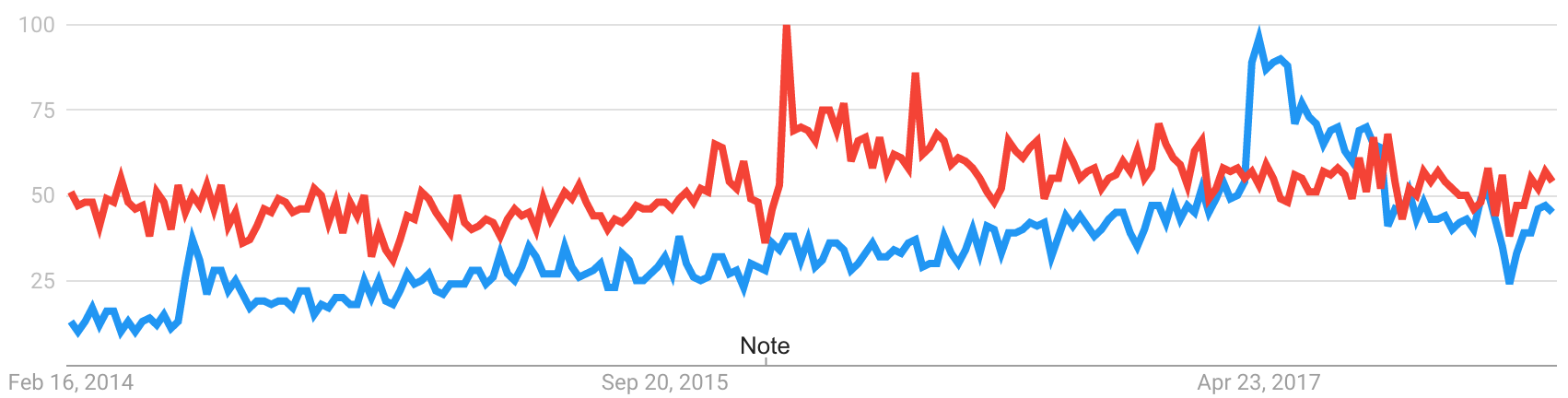
So what can we take from this? I think the right side of the graph is quite interesting. FHIR itself has kind of levelled off recently and has hit similar metrics to those of a very productive organization.
I probably shouldn't attach too much meaning to these graphs, but I can't help but wonder...
Custom Search Parameters in HAPI FHIR
HAPI FHIR's JPA Module lets you quickly set up a FHIR server, complete with a database for whatever purpose you might have.
One of the most requested features in the last year has been for support of custom search parameters on that server. Out of the box, the JPA server has always supported the default/built-in search parameters that are defined in the FHIR specification.
This means that if you store a Patient resource in the database, the Patient.gender field will be indexed with a search parameter called gender, the Patient.birthDate field will be indexed with a search parameter called birthdate, etc.
To see a list of the default search parameters for a given resource, you can see a table near the bottom of any resource definition. For example, here are the Patient search parameters.
The Need for Custom Parameters
The built-in parameters are great for lots of situations but if you're building a real application backend then you are probably going to come up with a need that the FHIR specification developers didn't anticipate (or one that doesn't meet FHIR's 80% rule).
The solution for this is to introduce a custom search parameter. Search parameters are defined using a resource that is – unsurprisingly – called SearchParameter. The idea is that you create one of these SearchParameter resources and give it a code (the name of the URL parameter), a type (the search parameter type), and an expression (the FHIRPath expression which will actually be indexed).
Custom Parameters in HAPI FHIR JPA
In HAPI FHIR's JPA server, custom search parameters are indexed just like any other search parameter. A new mechanism has been introduced in HAPI FHIR 2.3 (to be released soon) that parses the expression, adds any new or updated search parameters to an internal registry of indexed paths, and marks any existing resources that are potential candidates for this new search parameter as requiring reindexing.
This means that any newly added search parameters will cover resources added after the search parameter was added, and it will also cover older resources after the server has had a chance to reindex them.
This also means that you definitely want to make sure you have properly secured the /SearchParameter endpoint since it can potentially cause your server to do a lot of extra work if there are a lot of resources present.
Taking it for a Spin!
To show how this works, here is an example of a search parameter on an extension. We'll suppose that in our system we've defined an extension for patients' eye colour. Patient resources stored in our database will have the eye colour extension set, and we want to be able to search on this extension, too.
1. Create the Search Parameter
First, define a search parameter and upload it to your server. In Java, this looks as follows:
// Create a search parameter definition
SearchParameter eyeColourSp = new SearchParameter();
eyeColourSp.addBase("Patient");
eyeColourSp.setCode("eyecolour");
eyeColourSp.setType(org.hl7.fhir.dstu3.model.Enumerations.SearchParamType.TOKEN);
eyeColourSp.setTitle("Eye Colour");
eyeColourSp.setExpression("Patient.extension('http://acme.org/eyecolour')");
eyeColourSp.setXpathUsage(org.hl7.fhir.dstu3.model.SearchParameter.XPathUsageType.NORMAL);
eyeColourSp.setStatus(org.hl7.fhir.dstu3.model.Enumerations.PublicationStatus.ACTIVE);
// Upload it to the server
client
.create()
.resource(eyeColourSp)
.execute();The resulting SearchParameter resource looks as follows:
{
"resourceType": "SearchParameter",
"title": "Eye Colour",
"base": [ "Patient" ],
"status": "active",
"code": "eyecolour",
"type": "token",
"expression": "Patient.extension('http://acme.org/eyecolour')",
"xpathUsage": "normal"
}2. Upload Some Resources
Let's upload two Patient resources with different eye colours.
Patient p1 = new Patient();
p1.setActive(true);
p1.addExtension().setUrl("http://acme.org/eyecolour").setValue(new CodeType("blue"));
client
.create()
.resource(p1)
.execute();
Patient p2 = new Patient();
p2.setActive(true);
p2.addExtension().setUrl("http://acme.org/eyecolour").setValue(new CodeType("green"));
client
.create()
.resource(p2)
.execute();Here's how one of these resources will look when encoded.
{
"resourceType": "Patient",
"extension": [
{
"url": "http://acme.org/eyecolour",
"valueCode": "blue"
}
],
"active": true
}3. Search!
Finally, let's try searching:
Bundle bundle = ourClient
.search()
.forResource(Patient.class)
.where(new TokenClientParam("eyecolour").exactly().code("blue"))
.returnBundle(Bundle.class)
.execute();
System.out.println(myFhirCtx.newJsonParser().setPrettyPrint(true).encodeResourceToString(bundle));This produces a search result that contains only the matching resource:
{
"resourceType": "Bundle",
"id": "bc89e883-b9f7-4745-8c2f-24bf9277664d",
"meta": {
"lastUpdated": "2017-02-07T20:30:05.445-05:00"
},
"type": "searchset",
"total": 1,
"link": [
{
"relation": "self",
"url": "http://localhost:45481/fhir/context/Patient?eyecolour=blue"
}
],
"entry": [
{
"fullUrl": "http://localhost:45481/fhir/context/Patient/2",
"resource": {
"resourceType": "Patient",
"id": "2",
"meta": {
"versionId": "1",
"lastUpdated": "2017-02-07T20:30:05.317-05:00"
},
"text": {
"status": "generated",
"div": "<div xmlns=\"http://www.w3.org/1999/xhtml\"><table class=\"hapiPropertyTable\"><tbody/></table></div>"
},
"extension": [
{
"url": "http://acme.org/eyecolour",
"valueCode": "blue"
}
],
"active": true
},
"search": {
"mode": "match"
}
}
]
}Custom Search Parameters in Smile CDR
Naturally, this feature will soon be available in Smile CDR. Previous versions of Smile CDR had a less elegant solution to this problem; however, now that we have a nice elegant approach to custom parameters that is based on FHIR's own way of handling this, Smile CDR users will see the benefits quickly.
GitLab show us exactly how to handle an outage
I love GitLab. Let's get that out of the way.
Back when I first joined the HAPI project, we were using CVS for version control, hosted on SourceForge. Sourceforge was at that point a pretty cool system. You got free project hosting for your open source project, a free website, and shell access to a server so you could run scripts, edit your raw website, and whatever else you needed to do. That last part has always amazed me; I've always wondered what lengths SourceForge must have had to go to in order to keep that system from being abused.
Naturally, we eventually discovered GitHub and happily moved over there – and HAPI FHIR remains a happy resident of GitHub. We're now in the progress of migrating the HAPI Hl7v2.x codebase over to a new home on GitHub, too.
Along comes GitLab
The Smile CDR team discovered GitLab about a year ago. We quickly fell in love: easy self-hosting, a UI that feels familiar to a GitHub user yet somehow slightly more powerful in each part you touch, and a compelling set of features in the enterprise edition as well once you are ready for them.
On Tuesday afternoon, Diederik noticed that GitLab was behaving slowly. I was curious about it since GitLab's @gitlabstatus Twitter mentioned unknown issues affecting the site. As it turned out, their issues went from bad, to better, and then to much worse. Ultimately, they wound up being unavailable for all of last night and part of this morning.
A terrible day for them!
GitLab's issues were slightly hilarious but also totally relatable to anyone building and deploying big systems for any length of time. TechCrunch has a nice writeup of the incident if you want the gory details. Let's just say they had slowness problems caused by a user abusing the system, and in trying to recover from that a sysadmin accidentally deleted a large amount of production data. Ultimately, he thought he was in a shell on one (bad) node and just removing a useless empty directory but he was actually in a shell on the (good) master node.
I read a few meltdowns about this on reddit today, calling the sysadmin inexperienced, inept, or worse, but I also saw a few people saying something that resonated with me much more: if you've never made a mistake on a big complicated production system, you've probably never worked on a big complicated production system.
These things happen. The trick is being able to recover from whatever has gone wrong, no matter how bad things have gotten.
An exercise in good incident management
This is where GitLab really won me over. Check their Twitter for yourself. There was no attempt to mince words. GitLab engineers were candid about what had happened from the second things went south.
GitLab opened a publicly readable Google Doc where all of the notes of their investigation could be read by anyone wanting to follow along. When it became clear that the recovery effort was going to be long and complicated, they opened a YouTube live stream of a conference bridge with their engineers chipping away at the recovery.
They even opened a live chat with the stream so you could comment on their efforts. Watching it was great. I've been in their position many times in my life: tired from being up all night trying to fix something, and sitting on an endless bridge where I'm fixing one piece, waiting for others to fix theirs, and trying to keep morale up as best I can. GitLab's engineers did this, and they did it with cameras running.
So this is the thing: I bet GitLab will be doing a lot of soul-searching in the next few days, and hopefully their tired engineers will get some rest soon. In the end, the inconvenience of this outage will be forgotten but I'm sure this won't be the last time I'll point to the way they handled a critical incident with complete transparency, and set my mind at ease that things were under control.